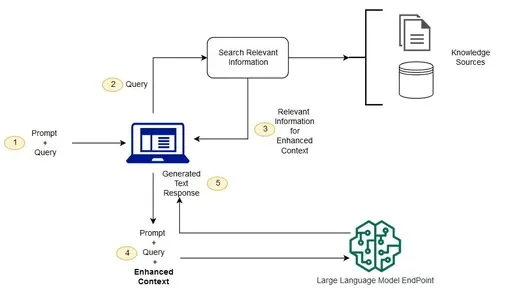
What is RAG (Retrieval Augmented Generation) ? RAG is an advanced model in the field of artificial intelligence that addresses a crucial challenge faced by large language models (LLMs). While LLMs are trained on massive datasets, they lack the ability to directly access or incorporate user-specific data. RAG addresses this limitation by integrating user data into the training process, enhancing the model’s capacity to provide personalized and contextually relevant responses.
**1. What is RAG Model:
Retrieval Augmented Generation (RAG) represents a significant advancement in natural language processing. Traditional large language models, such as GPT-3, are trained on extensive datasets but do not possess a mechanism for incorporating user-specific data. RAG introduces a solution to this problem by integrating user data into the training process, enabling the model to understand and respond to queries within a personalized context.
**2. Loading Stage: Bringing in User Data:
In the loading stage, user data is introduced to the system. This data can come in various forms, such as documents, API outputs, or information retrieved from databases. The fundamental units of this data are referred to as “Nodes” and “Documents.” A Document acts as a container for a specific data source, like a PDF file or a database, while a Node is the atomic unit of data, representing a distinct chunk of information within a Document.
To facilitate the loading of user data, connectors or data connectors, often called Readers, are employed. These connectors ingest data from diverse sources and formats, organizing it into Documents and Nodes for further processing. extract table from pdf rag model
Example: Consider a healthcare application where user data includes patient records (Documents) and individual health entries (Nodes) within those records.
**3. Indexing Stage: Preparing Data for Retrieval:

Once user data is loaded, it undergoes the indexing stage. In this stage, the data is organized into a structure that facilitates efficient retrieval. This involves the creation of “Indexes,” which store numerical representations called embeddings. Embeddings are generated by LLMs and serve as a way to filter and retrieve data relevant to user queries. extract table from pdf
Example: In the healthcare application, the indexing stage involves creating an index that allows for quick retrieval of specific patient information or health conditions.
**4. Querying Stage: Retrieving Relevant Information:
The querying stage involves the retrieval of relevant information based on user queries. Several components play crucial roles in this stage:
- Retrievers: These components efficiently fetch relevant context from the index when provided with a query. They act like information retrieval systems, quickly identifying and extracting data. rag model
- Routers: Routers determine which retriever to use based on the nature of the user query. They play a vital role in selecting the most appropriate method for retrieving information.
- Node Postprocessors: After retrieving nodes, postprocessors apply transformations, filtering, or re-ranking logic to ensure that the information presented to the user is the most relevant and useful.
- Response Synthesizers: These components generate responses from the LLM, utilizing the user query and the set of retrieved text chunks. They play a critical role in presenting coherent and meaningful answers to user queries. personal chat bot chat with your own data
Example: If a user in the healthcare application queries about a specific medical condition, the retriever quickly retrieves relevant patient records and health entries, the router determines the best way to retrieve this information, and postprocessors filter out unnecessary details for a concise response.
**5. Putting it All Together: Applications of RAG:

RAG can be applied to various use cases, broadly falling into three categories:
- Query Engines: These are end-to-end pipelines that allow users to ask questions over their data. Users input natural language queries, and the system returns responses along with reference context retrieved and passed to the LLM. What is RAG in LLM
- Chat Engines: Unlike traditional question-and-answer systems, chat engines facilitate multi-turn conversations with the data. Users can engage in back-and-forth interactions, obtaining more nuanced responses.
- Agents: Agents represent automated decision-makers powered by LLMs. They interact with the world through a set of tools, taking multiple steps to complete tasks. Agents dynamically decide on the best course of action rather than following pre-determined steps, providing flexibility for handling complex tasks.
Example: In a financial application, a query engine allows users to ask about their investment portfolio, a chat engine enables users to have detailed conversations about market trends, and an agent assists in dynamically adjusting investment strategies based on changing market conditions. personal chat bot chat with your own data
In conclusion, Retrieval Augmented Generation (RAG) stands as a powerful paradigm in AI, seamlessly integrating user-specific data into the training process of large language models. By doing so, RAG enhances the model’s ability to understand and respond to user queries within a personalized and contextually relevant framework. This approach opens up new possibilities for creating AI applications that go beyond generic responses, offering a tailored and dynamic interaction experience for users across various domains.
Retrieval Augmented Generation (RAG) BY IBM
- What is Deepfake AI | Is Deepfake legal in India
- How AI can helpful at Ram Mandir Ayodhya Safety on January 22, 2024
- How Infosys loses $1.5 billion AI contract from global customer
- What is RAG Model ? How does rag work ? Future of Technology
- What is LLM large language model | Important LLM’s in 2023
- What happens if you go on the dark web | Is dark web illegal in India 2023?



0 Comments